1、概述
为什么要优化
- 系统的吞吐量瓶颈往往出现在数据库的访问速度上;
- 随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢;
- 数据是存放在磁盘上的,读写速度无法和内存相比。
如何优化
- 设计数据库时:数据库表、字段的设计,存储引擎
- 利用好MySQL自身提供的功能,如索引等
- 横向扩展:MySQL集群、负载均衡、读写分离
- SQL语句的优化(收效甚微)
2、字段设计
- 尽量使用整型表示字符串;
- 尽可能选择小的数据类型和指定短的长度;
- 对于金额等使用定点数decimal,不会出现精度问题;
- 字段注释要完整,见名知意;
- 单表字段不宜过多;
- 尽可能使用not null,因为非null字段的处理要比null字段的处理高效些!且不需要判断是否为null。
- 可以预留字段,以满足业务需要。
3、存储引擎的选择
存储差异
| MyISAM | InnoDB | |
|---|---|---|
| 文件格式 | 数据和索引是分别存储的,数据.MYD,索引.MYI | 数据和索引是集中存储的,.ibd |
| 文件能否移动 | 能,一张表就对应.frm、MYD、MYI3个文件 | 否,因为关联的还有data下的其它文件 |
| 记录存储顺序 | 按记录插入顺序保存 | 按主键大小有序插入 |
| 空间碎片(删除记录并flush table 表名之后,表文件大小不变) | 产生。定时整理:使用命令optimize table 表名实现 | 不产生 |
| 事务 | 不支持 | 支持 |
| 外键 | 不支持 | 支持 |
| 锁支持(锁是避免资源争用的一个机制,MySQL锁对用户几乎是透明的) | 表级锁定 | 行级锁定、表级锁定,锁定粒度小并发能力高 |
选择依据
- 默认使用InnoDB;
- MyISAM:以读写插入为主的应用程序,比如博客系统,新闻门户网站;
- InnoDB:更新(删除)操作频繁,或者要保证数据的完整性;并发量高,支持事务和外键保证数据完整性,比如:OA自动化办公系统。
4、索引
索引为什么这么快
- 关键字相对数据本身,数据量小;
- 关键字是有序的,二分查找可快速确定位置
MySQL中的索引类型:
- 普通索引:对关键字没有限制;
- 唯一索引:要求记录提供的关键字不能重复;
- 主键索引:要求关键字唯一且不为null
执行计划explain
通过explain select 来分析SQL语句执行前的执行计划。
由上图可看出此SQL语句是按照主键索引来检索的。
执行计划是:当执行SQL语句时,首先会分析、优化,形成执行计划,再按照执行计划执行。
索引使用场景(重点)
where

上图中,根据id查询记录,因为id字段仅建立了主键索引,因此此SQL执行可选的索引只有主键索引,如果有多个,最终会选一个较优的作为检索的依据。
-- 增加一个没有建立索引的字段
alter table innodb1 add sex char(1);
-- 按sex检索时可选的索引为null
EXPLAIN SELECT * from innodb1 where sex='男';
可以尝试在一个字段未建立索引时,根据该字段查询的效率,然后对该字段建立索引(alter table 表名 add index(字段名)),同样的SQL执行的效率,你会发现查询效率会有明显的提升(数据量越大越明显)。
order by
当我们使用order by将查询结果按照某个字段排序时,如果该字段没有建立索引,那么执行计划会将查询出的所有数据使用外部排序(将数据从硬盘分批读取到内存使用内部排序,最后合并排序结果),这个操作是很影响性能的,因为需要将查询涉及到的所有数据从磁盘中读到内存(如果单条数据过大或者数据量过多都会降低效率),更无论读到内存之后的排序了。
但是如果我们对该字段建立索引alter table 表名 add index(字段名),那么由于索引本身是有序的,因此直接按照索引的顺序和映射关系逐条取出数据即可。而且如果分页的,那么只用取出索引表某个范围内的索引对应的数据,而不用像上述那取出所有数据进行排序再返回某个范围内的数据。
join
对join语句匹配关系(on)涉及的字段建立索引能够提高效率;
索引覆盖
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会做全表扫描),这叫索引覆盖。因此我们需要尽可能地在select后==只写必要的查询字段==,以增加索引覆盖的几率。
这里值得注意的是不要想着为每个字段建立索引,因为优先使用索引的优势就在于其体积小。
如何创建索引
- 建立基础索引:在where、order by、join字段上建立索引。
- 优化,组合索引:基于业务逻辑
- 如果条件经常性出现在一起,那么可以考虑将多字段索引升级为==复合索引==
- 如果通过增加个别字段的索引,就可以出现==索引覆盖==,那么可以考虑为该字段建立索引
- 查询时,不常用到的索引,应该删除掉
5、分区
一般情况下我们创建的表对应一组存储文件,使用MyISAM存储引擎时是一个.MYI和.MYD文件,使用Innodb存储引擎时是一个.ibd和.frm(表结构)文件。
当数据量较大时(一般千万条记录级别以上),MySQL的性能就会开始下降,这时我们就需要将数据分散到多组存储文件,==保证其单个文件的执行效率==。
最常见的分区方案是按id分区,如下将id的哈希值对10取模将数据均匀分散到10个.ibd存储文件中:
create table article(
id int auto_increment PRIMARY KEY,
title varchar(64),
content text
)PARTITION by HASH(id) PARTITIONS 10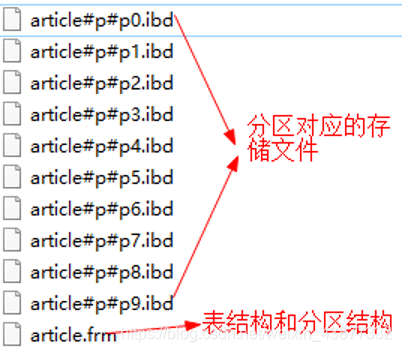
==服务端的表分区对于客户端是透明的==,客户端还是照常插入数据,但服务端会按照分区算法分散存储数据。
MySQL提供的分区算法
==分区依据的字段必须是主键的一部分==,分区是为了快速定位数据,因此该字段的搜索频次较高应作为强检索字段,否则依照该字段分区毫无意义。
hash(field)
相同的输入得到相同的输出。输出的结果跟输入是否具有规律无关。==仅适用于整型字段==
key(field)
和hash(field)的性质一样,只不过key是==处理字符串==的,比hash()多了一步从字符串中计算出一个整型在做取模操作。
range算法
是一种==条件分区==算法,按照数据大小范围分区(将数据使用某种条件,分散到不同的分区中)。
list算法
也是一种条件分区,按照列表值分区(in (值列表))。
分区的使用
当数据表中的数据量很大时,分区带来的效率提升才会显现出来。
只有检索字段为分区字段时,分区带来的效率提升才会比较明显。因此,==分区字段的选择很重要==,并且==业务逻辑要尽可能地根据分区字段做相应调整==(尽量使用分区字段作为查询条件)。
6、水平分割和垂直分割
水平分割:通过建立结构相同的几张表分别存储数据
垂直分割:将经常一起使用的字段放在一个单独的表中,分割后的表记录之间是一一对应关系。
分表原因
- 为数据库减压
- 分区算法局限
- 数据库支持不完善(5.1之后mysql才支持分区操作)
id重复的解决方案
借用第三方应用如memcache、redis的id自增器
单独建一张只包含id一个字段的表,每次自增该字段作为数据记录的id
7、集群
横向扩展:从根本上(单机的硬件处理能力有限)提升数据库性能 。由此而生的相关技术:==读写分离、负载均衡==
读写分离
读写分离是依赖于主从复制,而主从复制又是为读写分离服务的。因为主从复制要求slave不能写只能读(如果对slave执行写操作,那么show slave status将会呈现Slave_SQL_Running=NO,此时你需要按照前面提到的手动同步一下slave)。
负载均衡
负载均衡算法
- 轮询
- 加权轮询:按照处理能力来加权
- 负载分配:依据当前的空闲状态(但是测试每个节点的内存使用率、CPU利用率等,再做比较选出最闲的那个,效率太低)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!