1. 浏览器根据域名解析IP地址
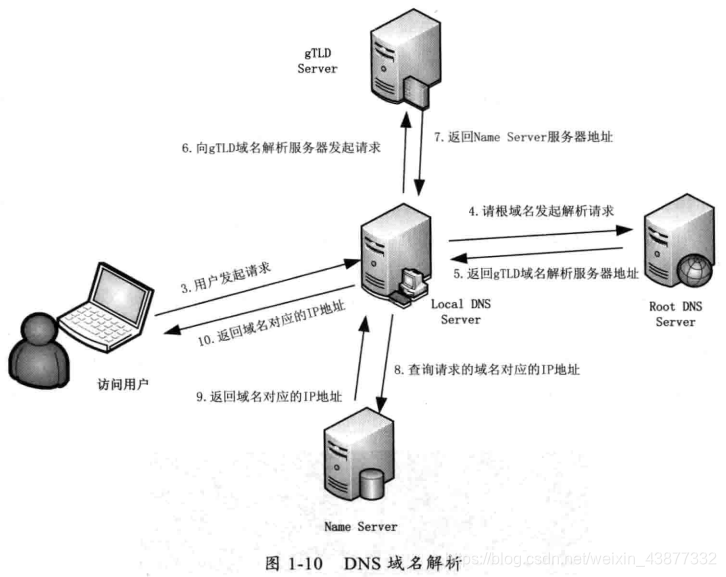
浏览器根据访问的域名找到其IP地址,DNS查找过程如下:
- 浏览器缓存:首先搜索浏览器自身的DNS缓存(缓存的时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否具有域名对应的条目,如果有且没有过期则解析到此结束。
- 系统缓存:如果浏览器自身的缓存里面没有找到对应的条目,那么浏览器会搜索操作系统自身的DNS缓存(Hosts文件),如果找到且没有过期则停止搜索,解析到此结束;
- 操作系统将这个域名发送给LDNS,也就是本地区的域名服务器(完成80%的域名解析工作);
- 如果LDNS没有,则直接到Root Server域名服务器请求解析;
- 根域名服务器返回给本地域名服务器一个所查询域的主域名服务器(gTLD Server)地址;
- 本地域名服务器(Local DNS Server)再向上一步返回的gTLD服务器发送请求;
- 接受请求的gTLD服务器查找并返回此域名对应的Name Server域名服务器(当时注册的域名服务器)的地址;
- Name Server域名服务器会查询存储的域名和IP的映射关系表;
- 返回该域名对应的IP和TTL值;
- 把解析的结果返回给用户,用户根据TTL值存储在本地系统缓存中,域名解析过程结束。
2 浏览器与Web服务器建立一个TCP连接
TCP的三次握手
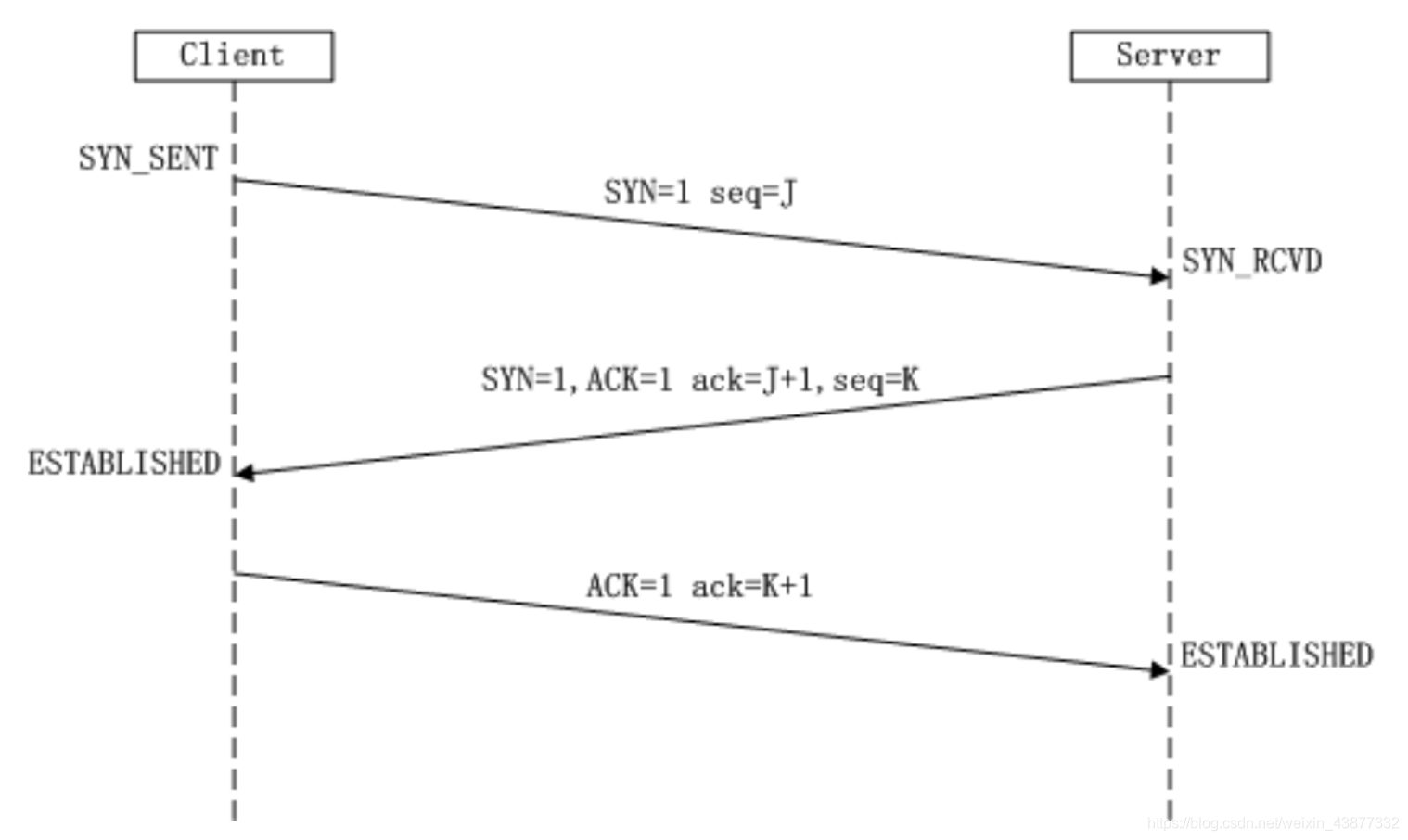
- 第一次握手:客户端发送网络包,服务端收到了,这样服务端就能得出结论:客户端的发送能力,服务端的接收能力是正常的;
- 第二次握手:服务端发包,客户端收到了,这样客户端就能得到结论:服务端的发送和接收能力,客户端的发送和接收能力是正常的,但此时服务端并不知道自己的发送能力以及客户端的接收能力是否正常,所以还需要第三次握手;
- 第三次握手:客户端发包,服务端收到,这样服务端得出结论,服务端的发送和客户端的接收能力正常,可以正常通信了。
3. 浏览器给Web服务器发送一个HTTP请求
一个HTTP请求报文由请求行(request line),请求头部(headers),空行(blank line)和请求数据(request body)4个部分组成。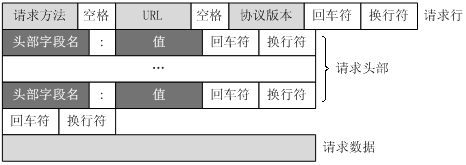
3.1 请求行
请求行分为三个部分:请求方法,请求地址URL和HTTP协议版本,它们之前用空格分隔,例如:GET /index.html HTTP/1.1
3.1.1请求方法
HTTP/1.1定义的请求方法有8种:GET(完整请求一个资源),POST(提交表单),PUT(上传文件),DELETE(删除),PATCH,HEAD(仅请求响应首部),OPTIONS(返回请求的资源所支持的方法),TRACE(追求一个资源请求中间所经过的代理),RESTful接口的话一般会用到GET,POST,DELETE,PUT。
GET
当客户端要从服务器中读取文档时,当点击网页上的链接或者通过在浏览器的地址栏输入网址来浏览网页,使用的都是GET方式,GET方法要求服务器将URL定位的资源放在响应报文的数据部分,会送给客户端。
使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号?代表URL的结尾与请求参数的开始,多个参数之间用&符号分开,不适合传输私密数据,另外传递参数长度也有限制。
GET请求不会对服务器产生任何其他影响,仅仅是获取数据。
POST
允许客户端给服务器提供信息较多,POST方法将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据,同时参数也不会显示在URL栏中,POST方式大多用于页面的表单中。
POST是客户端向服务器提交数据的方法,这种方法会影响服务器,服务器可能根据收到的数据动态创建新的资源,也可能更新原有的资源。
3.1.2 请求地址URL
URL:统一资源定位符,是一种资源位置的抽象唯一识别方法。
组成:<协议>://<主机>:<端口>/<路径>
端口和路径有时可以省略(HTTP默认端口号是80)
3.1.3 协议版本
协议版本的格式为:HTTP/主版本号.次版本号,常用的有:HTTP/1.0 和 HTTP/1.1。
3.2 请求头部
请求头部为请求报文添加了一些附加信息,如:主机名,发送请求的应用程序名称等,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
请求头部的最后会有一个空格,表示请求头部结束,接下来为请求数据。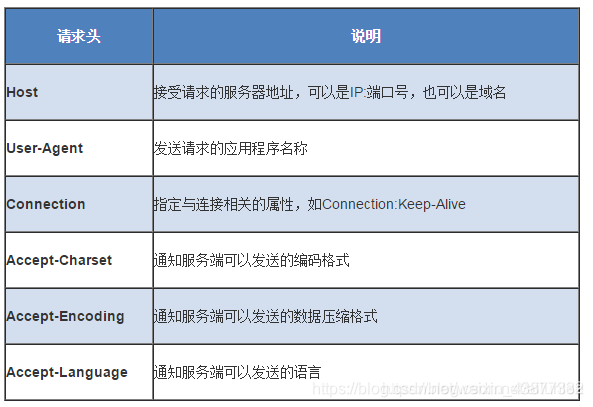
3.3 请求数据
请求数据不在GET方法中使用,而是在POST方法中使用,POST方法适用于需要客户填写表单的场合,与请求数据相关的最常使用的请求头部是Content-Type和Content-Length。下面是一个POST方法的请求报文:
POST /index.php HTTP/1.1 请求行
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:10.0.2) Gecko/20100101 Firefox/10.0.2 请求头
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8
Accept-Language: zh-cn,zh;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Referer: http://localhost/
Content-Length:25
Content-Type:application/x-www-form-urlencoded
空行
username=aa&password=1234 请求数据4. 服务器端响应HTTP请求,浏览器得到HTML代码
HTTP响应报文由状态行(status line),响应头部(headers),空行(blank line)和响应数据(response body)4个部分组成。
4.1 状态行
状态行由3部分组成,分别为:协议版本,状态码,状态信息。其中协议版本与请求报文一致,状态信息是对状态码的简单描述。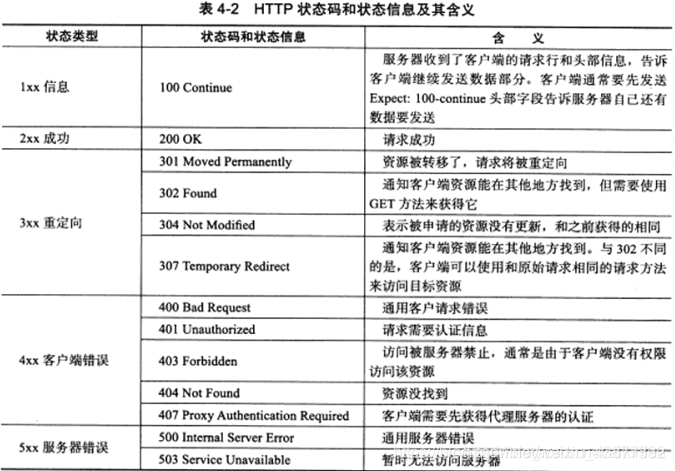
4.2 响应头部
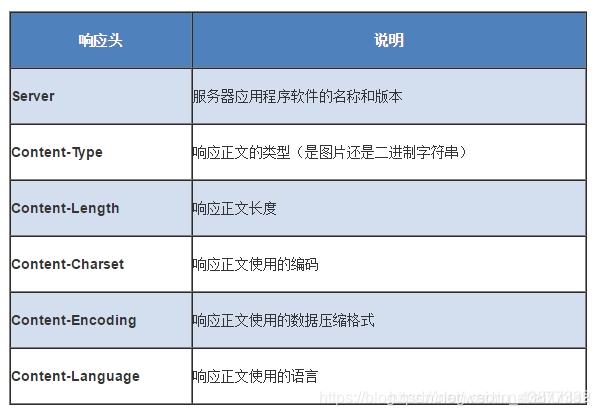
4.3 响应数据
用于存放需要返回给客户端的数据信息。
HTTP/1.1 200 OK 状态行
Date: Sun, 17 Mar 2013 08:12:54 GMT 响应头部
Server: Apache/2.2.8 (Win32) PHP/5.2.5
X-Powered-By: PHP/5.2.5
Set-Cookie: PHPSESSID=c0huq7pdkmm5gg6osoe3mgjmm3; path=/
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Content-Length: 4393
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Content-Type: text/html; charset=utf-8
空行
<html> 响应数据
<head>
<title>HTTP响应示例<title>
</head>
<body>
Hello HTTP!
</body>
</html>5. 浏览器解析HTML代码,并请求HTML代码中的资源
浏览器拿到HTML文件后,开始解析HTML代码,遇到静态资源时,就向服务器去请求下载。
6. 关闭TCP连接,浏览器对页面进行渲染呈现给用户
浏览器利用自己内部的工作机制,把请求到的静态资源和HTML代码进行渲染,呈现给用户。
参考:
1、HTTP请求的完全过程
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!