Java概述
1. JVM、JRE和JDK的关系
JVMJava Virtual Machine,是Java虚拟机,Java程序需要运行在虚拟机上,不同的平台有自己的虚拟机,因此Java语言可以实现跨平台。
JREJava Runtime Environment,包括Java虚拟机和Java程序所需的核心类库等。核心类库主要是java.lang包:包含了运行Java程序必不可少的系统类,如基本数据类型、基本数学函数、字符串处理、线程、异常处理类等,系统缺省加载这个包;
如果想要运行一个开发好的Java程序,计算机中只需要安装JRE即可。
JDKJava Development Kit,是提供给Java开发人员使用的,其中包含了Java的开发工具,也包括了JRE。所以安装了JDK,就无需再单独安装JRE了。其中的开发工具:编译工具(javac.exe),打包工具(jar.exe)等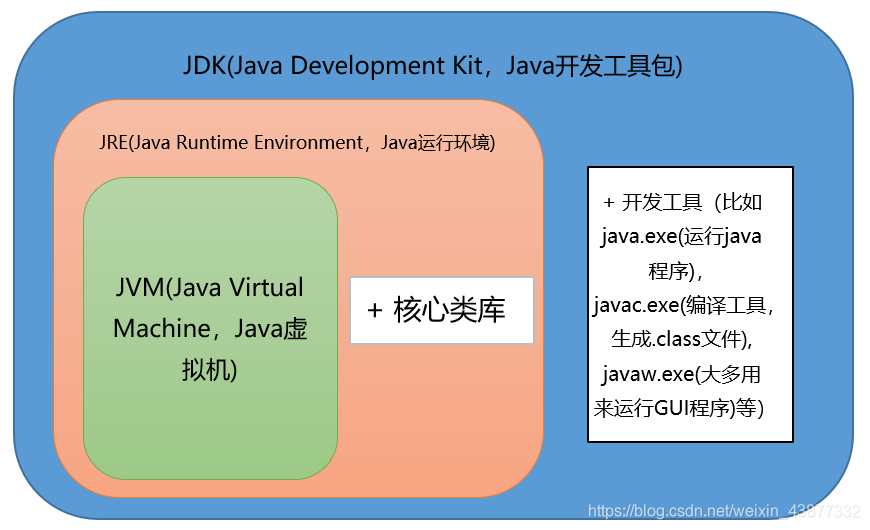
2. Java与C#的区别与联系
相同点:
都是面向对象编程的语言,都能够实现面向对象的思想(封装,继承,多态);都具有垃圾自动回收机制;Java站在C++的肩膀上,而C#站在了Java的肩膀上。
不同点:
- 语法特性: Java抛弃了指针,使用了包(package)的概念,导入包使用import语句;C#没有完全抛弃指针(在unsafe状态下还可以操作指针),对于类的管理采用了名称空间(namespace)的概念,并且还使用了out、ref等关键字,便于从一个方法返回多个结果。
- 功能方面:C#有一些由编译器提供的特性,如:委托、属性、真正的泛型等,在Java中实现起来有点麻烦,同样Java中也有C#不具备的功能,如匿名内部类,动态代理等,另外Java实现了真正的跨平台性,而C#的跨平台性是建立在跨windows平台的基础上的。
3. Java与C/C++的异同
- Java是解释型语言,C/C++为编译型语言,源代码经过编译和链接后生成可执行的二进制代码,Java执行速度比C/C++慢,但Java能够跨平台执行;
- Java为纯面向对象语言,不存在全局变量或全局函数;
- Java没有指针的概念;
- Java不支持多重继承
- Java提供了垃圾回收器来实现垃圾的自动回收,C++通常会把需要释放资源的代码放到析构函数中;
- Java具有平台无关性,即对每种数据类型都分配固定长度。
4. Oracle JDK和OpenJDK的对比
OpenJDk版本每三个月发布一次,而OracleJDK每三年发布一次;
OpenJDK是一个参考模型并且完全开源,而OracleJDK是OpenJDK的一个实现,并不是完全开源的;
OracleJDK比OpenJDK更稳定,性能更好
基础语法
1、 switch能否作用在byte上,是否能作用在long上,是否能作用在String上?
在 Java 5 以前,switch(expr)中,expr 只能是 byte、short、char、int。从 Java5 开始,Java 中引入了枚举类型,expr 也可以是 enum 类型,从 Java 7 开始,expr 还可以是字符串(String),但是长整型(long)在目前所有的版本中都是不可以的。
原因是switch在编译时被编译成对应的两个实现方式的指令,而这两个指令只支持int类型。
2、Java语言采用何种编码方式,有什么特点?
Java语言采用Unicode编码标准,Unicode(标准码),它为每个字符制订了一个唯一的数值,因此在任何的语言,平台,程序都可以放心的使用。
Unicode 编码共有三种具体实现,分别为utf-8,utf-16,utf-32,其中utf-8占用一到四个字节,utf-16占用二或四个字节,utf-32占用四个字节
3、super关键字的用法
super可以理解为是指向自己超(父)类对象的一个指针。
A:可以利用super关键字代表父类对象访问父类的属性和方法;
super.属性 —-> 访问父类的属性
super.方法名()—- > 调用父类的方法
B:可以使用super关键字调用父类的构造函数,必须出现在构造函数的第一行;
C:super不能和static混用,因为super指的是对象,而static代表的是类。
4、static关键字的意义
主要意义是在于创建独立于具体对象的域变量或者方法,以至于即使没有创建对象,也能使用属性和调用方法!
另外还可以用来形成静态代码块用来优化程序性能,因为static块在类加载的时候仅会执行一次,所以可以将一些只需要进行一次的初始化操作都放在static代码块中进行;
利用static实现单例模式:
public class Singleton{
private static class SingletonHolder{
private static final Singleton INSTANCE = new Singleton();
}
private Singleton(){
}
public static final Singleton getInstance(){
return SingletonHolder.INSTANCE;
}
}5、final关键字
在Java中,final关键字可以用来修饰类,方法和变量(包括成员变量和局部变量)
1、修饰类
当用final修饰一个类时,表明这个类不能被继承。也就是说,如果一个类你永远不会让它被继承,就可以用final进行修饰。final类中的成员变量可以根据需要设为final,但是要注意final类中的所有成员方法都会被隐式地指定为final方法。
2、修饰方法
final修饰的方法表示此方法已经是“最后的、最终的”含义,亦即此方法不能被重写(可以重载多个final修饰的方法)。如果父类中final修饰的方法同时访问控制权限为private,将会导致子类中不能直接继承到此方法,此时可以在子类中定义相同的方法名和参数,不会产生重写与final的矛盾,而是在子类中重新定义了新的方法。(注:类的private方法会隐式地被指定为final方法。)
3、修饰变量
final成员变量表示常量,只能被赋值一次,赋值后值不再改变。
当final修饰一个基本数据类型时,表示该基本数据类型的值一旦在初始化后便不能发生变化;如果final修饰一个引用类型时,则在对其初始化之后便不能再让其指向其他对象了,但该引用所指向的对象的内容是可以发生变化的。本质上是一回事,因为引用的值是一个地址,final要求值,即地址的值不发生变化。
final修饰一个成员变量(属性),必须要显式初始化。这里有两种初始化方式,一种是在变量声明的时候初始化;第二种方法是在声明变量的时候不赋初值,但是要在这个变量所在的类的构造函数中对这个变量赋初值。
如果不在定义的时候或者构造函数中对final变量进行赋值的话,则生成的对象中final变量的值是未知的(编译器会直接报错),因此必须初始化。
如果用static final同时修饰变量的话,则变量必须在定义的时候进行初始化,因为static变量属于类,在调用构造函数之前就已经被系统赋予默认值了。
如果定义了static final还可以用静态代码块进行初始化,只定义了final还可以用代码块进行初始化(不能用静态代码块)。
6、创建String的两种方式:
- 通过字面量来创建:String s = “abc”;
- 通过new(构造方法)来创建:String s = new String(“abc”);
通过字面量来创建,首先会去字符串缓冲池寻找相同内容的字符串,如果存在就直接拿出来应用,如果不存在则创建一个新的字符串放在缓冲池中;
通过构造方法来创建字符串对象时,每次都会创建一个新的对象。
面向对象
1、面向对象和面向过程的区别
面向过程注重的是性能,因为面向对象万物皆对象,而类调用时需要实例化,开销比较大,比较消耗资源;
面向对象易维护,易复用,易扩展,主要是得益于面向对象的封装,继承,多态特性,可以设计出低耦合的系统;
2、什么是多态机制?Java中是如何实现多态的?
对于面向对象而言,多态分为编译时多态和运行时多态,其中编译时多态是静态的,主要是指方法的重载,它是根据参数列表的不同来区分不同的函数,而运行时多态是动态的,通过动态绑定来实现,多态性就是相同的消息使得不同的类做出不同的响应。
多态性体现在父类中定义的属性和方法被子类继承后,可以具有不同的属性或表现方式,多态性允许一个接口被多个同类使用,弥补了单继承的不足。
Java的多态是通过继承、重写、重载来实现的。
3、面向对象的五大基本原则?
单一职责原则:类的功能要单一
开放封闭原则:对扩展开放,对修改关闭
里氏替换原则:任何父类可以出现的地方,子类一定可以出现。
- 子类可以实现父类的抽象方法,但是不能覆盖父类的非抽象方法;
- 子类中可以增加自己特有的方法;
- 当子类覆盖或实现父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更加宽松;
- 当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更加严格。
依赖倒置原则:高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象
接口分离原则:设计时采用多个与特定客户类有关的接口比采用一个通用的接口要好
4、对象实例和对象引用有什么不同?
对象实例存储在堆上,对象引用存储在栈中,要访问对象实例可以通过对象引用来访问。
5、成员变量和局部变量的区别有哪些?
作用域
成员变量:针对整个类有效
局部变量:只在某个范围内有效
存储位置
成员变量:存储在堆中
局部变量:存储在栈内存中
生命周期
成员变量:随着对象的创建而存在,随着对象的消失而消失
局部变量:当方法调用完,或者语句结束后,就自动释放
初始值
成员变量:有默认初始值
局部变量:没有默认初始值,使用前必须赋值
6、在Java中定义一个不做事且没有参数的构造方法的作用
Java程序在执行子类的构造方法之前,如果没有用super()来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”,因此,如果父类中只定义了有参数的构造方法,而在子类中的构造方法中又没有用super()来调用父类中特定的构造方法,则会在编译时发生错误。
7、在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是什么
帮助子类做初始化工作,因为子类拥有父类的成员变量和成员方法,如果不调用,则从父类继承而来的成员变量和成员方法得不到正确的初始化。
8、构造方法有哪些特性?
- 方法名和类名相同
- 没有返回值,但不能用void声明构造函数
- 生成类的对象时自动执行,无需调用
9、静态变量、实例变量的区别
静态变量:静态变量不属于任何实例对象,而属于类,所以在内存中只会存在一份,在类的加载过程中,JVM只为静态变量分配一次内存空间;
实例变量:每次创建对象,都会为每个对象分配成员变量内存空间,实例变量属于实例对象,在内存中创建几次对象,就会有几份成员变量。
10、内部类的优点?有哪些应用场景
优点:
- 一个内部类对象可以访问创建它的外部类对象的内容,包括私有数据;
- 内部类不为同一包的其他类所见,具有很好的封装性;
- 内部类有效实现了“多重继承”,优化Java单继承的缺陷;
- 匿名内部类可以很方便的实现回调。
应用场景:
- 一些多算法场合;
- 解决一些非面向对象的语句块;
- 适当使用内部类,使得代码更加灵活和富有扩展性;
- 当某个类除了它的外部类,不再被其他的类使用时;
11、匿名内部类
public class Outer {
private void test(final int i) {
new Service() {
public void method() {
for (int j = 0; j < i; j++) {
System.out.println("匿名内部类" );
}
}
}.method();
}
}
//匿名内部类必须继承一个抽象类或实现一个已有的接口
interface Service{
void method();
}特点:
- 匿名内部类必须继承一个抽象类或者实现一个接口
- 匿名内部类不能定义任何静态成员和静态方法
- 当所在的方法的形参需要被匿名内部类使用时,必须声明为final
- 匿名内部类不能是抽象的,它必须要实现继承的类或者实现接口的所有方法
11、局部内部类和匿名内部类访问局部变量的时候,为什么变量必须要加final
用final修饰实际上是为了保护数据的一致性,因为如果局部变量发生变化后,匿名内部类或局部内部类是不知道的(因为它只是拷贝了局部变量的值,并不是直接使用的局部变量),如果过了一段时间后局部变量的值指向另外一个对象,或是值发生了改变,那么程序运行的结果和预期的会不一致。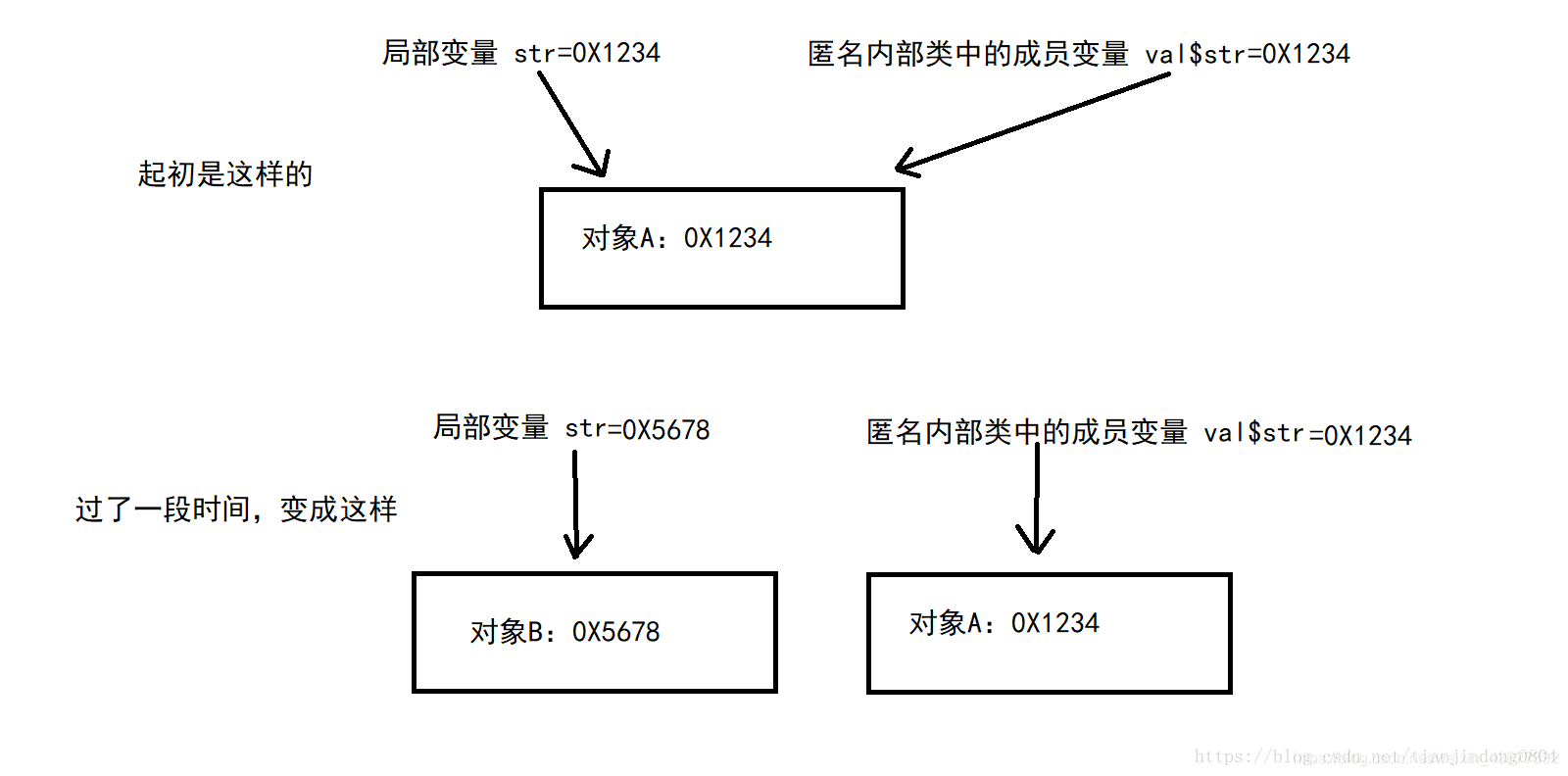
JDK1.8中虽然局部变量不需要用final修饰符修饰,但是我们在试图改变这个局部变量的时候会提示编译出错。
12、重载的方法能否根据返回类型进行区分
重载发生在同一个类中,方法名相同但参数列表不同(参数类型不同、个数不同、顺序不同),与方法返回值和访问修饰符无关。
13、hashcode和equals
这个问题应该是有个前提,就是你需要用到 HashMap、HashSet 等 Java 集合,用不到哈希表的话,其实仅仅重写 equals() 方法也可以。而工作中的场景是常常用到 Java 集合,所以 Java 官方建议重写 equals() 就一定要重写 hashCode() 方法。
对于对象集合的判重,如果一个集合含有 10000 个对象实例,仅仅使用 equals() 方法的话,那么对于一个对象判重就需要比较 10000 次,随着集合规模的增大,时间开销是很大的。但是同时使用哈希表的话,就能快速定位到对象的大概存储位置,并且在定位到大概存储位置后,后续比较过程中,如果两个对象的 hashCode 不相同,也不再需要调用 equals() 方法,从而大大减少了 equals() 比较次数。
hashCode()与equals()的相关规定:
1、如果两个对象相等,则 hashCode 一定也是相同的;
2、两个对象相等,对两个对象分别调用 equals 方法都返回 true;
3、两个对象有相同的 hashCode 值,它们也不一定是相等的;
4、因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖;
5、hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
14、当一个对象被当作参数传递到一个方法后,此方法可改变整个对象的属性,并返回变化后的结果,那么这里到底是值传递还是引用传递
是值传递。Java语言的方法调用只支持参数的值传递。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的属性可以在被调用过程中被改变,但对对象引用的改变是不会影响到调用者的,也就是说这个引用还是会指向之前的对象,而不会指向其他对象。之所以能修改引用数据是因为它们同时指向了一个对象。
15、值传递和引用传递的区别
所谓的按值调用表示方法接收的是调用者提供的值,而按引用调用则表示方法接收的是调用者提供的变量地址,一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。
16、import java和javax有什么区别
实际上java和javax没有区别。这都是一个名字。
17、Stream
Stream 就好像一个高级的迭代器,但只能遍历一次,在流的过程中,对流中的元素执行一些操作,比如“过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等。
要想操作流,首先需要有一个数据源,可以是数组或者集合,每次操作都会返回一个新的流对象,方便进行链式操作,但原有的流对象会保持不变。
如果数据源是数组,可以使用Arrays.stream()或者Stream.of()创建流;
如果是集合,直接使用stream()方法即可。
流的操作分为两种类型:
- 中间操作:可以有多个,每次返回一个新的流,可以进行链式操作;
- 终端操作:只能有一个,每次执行完,这个流也就用完了,无法执行下一个操作,因此只能放在最后。
List<String> list = new ArrayList<>();
list.add("江南飞鹏");
list.add("江南");
list.add("飞鹏");
list.add("江南飞鹏");
long count = list.stream().distinct().count();
System.out.println(count);distinct() 方法是一个中间操作(去重),它会返回一个新的流(没有共同元素)。
count() 方法是一个终端操作,返回流中的元素个数。
中间操作不会立即执行,只有等到终端操作的时候,流才开始真正地遍历,用于映射、过滤等。通俗点说,就是一次遍历执行多个操作,性能就大大提高了。
可以通过操作流来实现过滤、映射、匹配、组合等功能。
IO流
1.同步、异步、阻塞、非阻塞的区别
同步和异步:
同步:同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。
异步:异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但此时结果并没有返回,此时调用者可以处理其他的请求,被调用者通常依靠事件、回调等机制来通知调用者其返回结果。
同步和异步最大区别在于异步的话不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果
阻塞和非阻塞:
阻塞:阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续
非阻塞:非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
同步和异步关注的是消息通信机制:
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用的结果。而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来告诉调用者,或通过回调函数处理这个调用。
比如说:
你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下”,然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态:
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子,你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。
2.BIO、NIO、AIO有什么区别
BIO:同步阻塞I/O模型,数据的读取写入必须阻塞在一个线程内等待其完成
采用BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接,我们一般通过在while(true)循环中服务端会调用accept()方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就建立通信套接字来进行读写操作,如果要让BIO通信模型能够同时处理多个客户端的请求,就必须使用多线程,也就是说它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理。为了减少线程创建和销毁带来的开销,可以采用线程池的方式来管理线程。
NIO:同步非阻塞的I/O模型
Java NIO使我们可以进行非阻塞IO操作,比如单线程从通道读取数据到buffer,同时可以继续做别的事情,当数据读取到buffer中后,线程在继续处理数据,写数据同样如此。
NIO类库中加入了Buffer对象,在NIO库中,所有数据都是用缓冲区处理的,每种Java基本类型(除了Boolean)都对应一种缓冲区。
Channel(通道):NIO通过Channel进行读写,通道是双向的,可读也可写,而IO中的流是单向的,Channel只能和Buffer交互,因为Buffer,通道可以异步地读写。
Selector(选择器):选择器用于使用单个线程处理多个通道。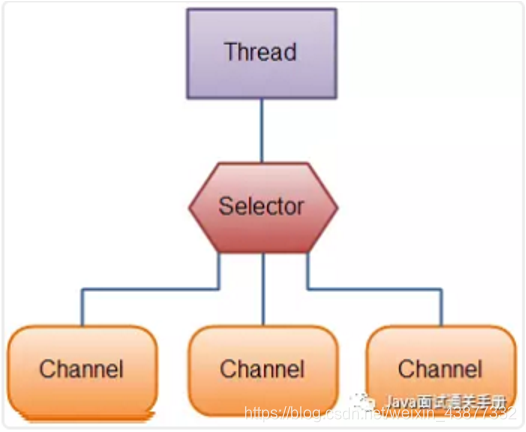
AIO:异步IO
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
3.Files常用方法有哪些
Files. exists():检测文件路径是否存在。
Files. createFile():创建文件。
Files. createDirectory():创建文件夹。
Files. delete():删除一个文件或目录。
Files. copy():复制文件。
Files. move():移动文件。
Files. size():查看文件个数。
Files. read():读取文件。
Files. write():写入文件。
反射
什么是反射机制
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
反射机制的优缺点
优点:可以动态执行,在运行期间根据业务功能动态执行方法、访问属性,最大限度发挥了java的灵活性。
缺点:对性能有影响,这类操作总是慢于直接执行java代码;使内部暴露,破坏封装;反射技术要求程序必须在一个没有安全限制的环境中运行。
反射机制的应用场景
- 在使用JDBC连接数据库时使用Class.forName(),通过反射加载数据库的驱动程序;
- Spring框架也用到很多反射机制,最经典的就是xml的配置模式;
- Web服务器中利用反射调用了Sevlet的服务方法。
- IDEA等开发工具利用反射动态剖析对象的类型与结构,动态提示对象的属性和方法。
Java获取反射的三种方法
1.通过new对象实现反射
2.通过路径实现反射机制
3.通过类名实现反射机制
public class Get {
//获取反射机制三种方式
public static void main(String[] args) throws ClassNotFoundException {
//方式一(通过建立对象)
Student stu = new Student();
Class classobj1 = stu.getClass();
System.out.println(classobj1.getName());
//方式二(通过路径-相对路径)
Class classobj2 = Class.forName("fanshe.Student");
System.out.println(classobj2.getName());
//方式三(通过类名)
Class classobj3 = Student.class;
System.out.println(classobj3.getName());
}
}public class Student {
private int id;
String name;
protected boolean sex;
public float score;
}自定义注解
@Retention(RetentionPolicy.RUNTIME)
@Target(value = {ElementType.TYPE})
@Documented
public @interface SecondAnnotation {
String value();
}- @Target注解,是专门用来限定某个自定义注解能够被应用在哪些Java元素上面的。
- @Retention注解,用来修饰自定义注解的生命力。
注解的生命周期有三个阶段:1、Java源文件阶段;2、编译到class文件阶段;3、运行期阶段。 - @Documented注解,是被用来指定自定义注解是否能随着被定义的java文件生成到JavaDoc文档当中。
- @Inherited注解,是指定某个自定义注解如果写在了父类的声明部分,那么子类的声明部分也能自动拥有该注解。@Inherited注解只对那些@Target被定义为ElementType.TYPE的自定义注解起作用。
自定义注解类编写的一些规则:
Annotation型定义为@interface所有的Annotation会自动继承java.lang.Annotation这一接口,并且不能再去继承别的类或是接口;- 参数成员只能用
public或默认(default)这两个访问权修饰; - 参数成员只能用基本类型
byte,short,char,int,long,float,double,boolean八种基本数据类型和String、Enum、Class、annotations等数据类型,以及这一些类型的数组; - 如果只有一个成员,成员名称最好用
value,因为默认就是它; - 一般定义参数成员后,都会给一个默认值,注意
String一般不用null做默认值,可以用字符串或空串(”“); - 要获取类方法和字段的注解信息,必须通过
Java的反射技术来获取Annotation对象,因为你除此之外没有别的获取注解对象的方法; - 注解也可以没有定义成员,不过这样注解就没啥用了
序列化
什么是序列化和反序列化?
- Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是把字节序列恢复为Java对象的过程;
- 序列化:最主要的用处是在传递和保存对象的时候,保证对象的完整性和可传递性,序列化是把对象转换成有序字节流,以便在网络中传输或者保存在本地文件中,序列化后的字节流保存了Java对象的状态以及相关的描述信息,序列化机制的核心作用就是对象状态的保存和重建。
- 反序列化:客户端从文件或网络上获得序列化后的对象字节流后,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。
- 从本质上讲,序列化就是把实体对象状态按照一定的格式写入到有序字节流,反序列化就是从有序字节流重建对象,恢复对象状态。
为什么需要序列化和反序列化?
Java序列化的好处:
- 实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘;
- 实现远程通信,即在网络上传输对象的字节序列。
Java是如何实现序列化和反序列化的?
1. JDK类库中序列化和反序列化API
java.io.ObjectOutputStream:表示对象输出流,它的writeObject(Object obj)方法可以对参数指令的obj对象进行序列化,把得到的字节序列写到一个目标输出流中;
java.io.ObjectInputStream:表示对象输入流,它的readObject()方法从输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回;
2. 实现序列化的要求
实现Serializable或Externalizable接口的类的对象才能被序列化,否则抛出异常。
3. JDK类库中序列化的步骤
创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流:
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("D:\\object.out"));通过对象输出流的writeObject()方法写对象:
oos.writeObject(new User("yyj","123","male"));
4. JDK类库中反序列化的步骤
创建一个对象输入流,它可以包装一个其他类型输入流,如文件输入流:
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("D:\\object.out"));通过对象输入流的readObject()方法读取对象:
User user = (User)ois.readObject();
说明:为了正确读取数据,完成反序列化,必须保证向对象输出流写对象的顺序与从对象输入流中读对象的顺序一致。
注意事项
- 序列化时,只对对象的状态进行保存,而不管对象的方法;
- 当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口;
- 当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;
- 并非所有对象都可以进行序列化,如声明为
static和transient类型的成员数据不能被序列化; - 序列化运行时使用一个称为serialVersionUID的版本号与每个可序列化类相关联;
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!