Redis支持以下五种数据结构:
- String类型
- List类型
- Set类型
- SortedSet类型
- Hash类型
| 存储极限 | 大小 |
|---|---|
| String类型的value大小 | 512M |
| Hash类型key的键值对大小 | 4294967295 |
| List类型的key个数 | 4294967295 |
| Set/SortedSet类型的key个数 | 4294967295 |
一、String(字符串)类型
在前面两章中,我们存储的都是 String 类型。该类型增加和删除一个键值对十分简单,如下:
| 含义 | 方法 |
|---|---|
| 获取值 | get key |
| 添加一个键值对 | set key value |
| 获取并重置一个键值对 | getset key value |
| 删除一个键值对 | del key |
字符串也可以进行数值操作(Redis内部自动将value转换为数值型),方法如下:
| 方法 | 含义 |
|---|---|
| incr key | 值加1 |
| decr key | 值减1 |
| incrby key n | 值加n |
| decrby key n | 值减n |
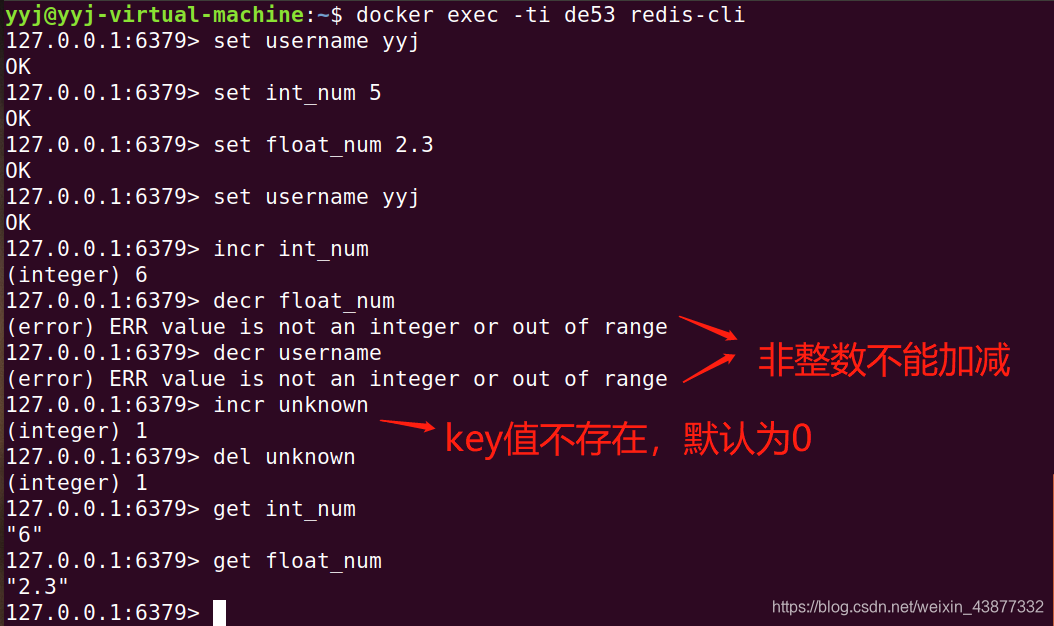
如果key值不存在,当做0处理,如果value值无法转换为整型时,会返回错误信息:
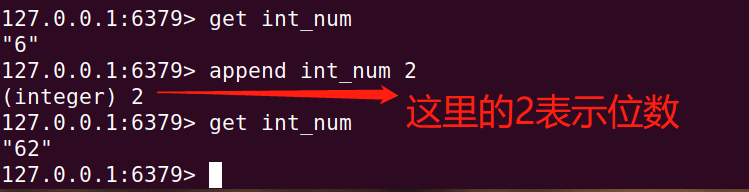
介绍一下字符串拼接方法,如下:
| 方法 | 含义 |
|---|---|
| append key | 拼接字符串 |
底层结构
Redis设计了一种简单动态字符串SDS作为底层实现,此对象包含三个属性:
- len:buf中已经占用的长度;
- free:buf中未使用的缓冲区长度;
- buf[]:实际保存字符串数据的地方;
好处
1、常数复杂度获取字符串长度
通过strlen key命令获取key的字符串长度,其时间复杂度变为O(1)。
2、杜绝缓冲区溢出
对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后再进行修改操作,所以不会出现缓冲区溢出。
3、减少修改字符串的内存重新分配次数
通过未使用空间,SDS实现了空间预分配和惰性空间释放两种优化策略。
空间预分配:
当len小于IMB(10241024)时*增加字符串分配空间大小为原来的2倍+1字节,当len大于等于1M时每次分配额外多分配1M**的空间。好处是SDS将连续增长N次字符串所需的内存重分配次数从必然N次降低为最多N次。
惰性空间释放:
用于优化SDS字符串缩短操作,当SDS的API需要缩短SDS保存的字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用free属性来将这些字节的数量记录起来,并等待将来使用。
通过惰性空间释放策略,SDS避免了缩短字符串时所需的内存重分配操作,并为将来有可能的增长操作提供了优化。
4、二进制安全
因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。
5、兼容部分C 字符串函数
因为buf[]中依然采用了C语言的以\0结尾,因此可以直接使用C语言的部分标准C字符串库函数。
二、Hash(散列)类型
Redis的字典使用哈希表作为底层实现。
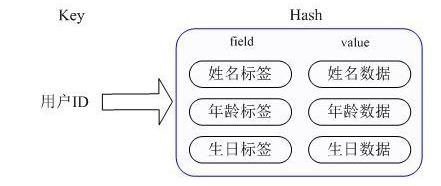
散列,即 Hash,Redis 中的 Hash 类型可以看成Map集合。Hash 类型的每一个 key 的 value 对应于一个 Map,该Map包含多个键值对的数据,如下图所示:
2.1 赋值
| 方法 | 含义 |
|---|---|
| hset key field value | 为指定key设置一个键值对 |
| hmset key field value[field2 value2…] | 为指定key设置多个键值对 |

2.2 取值
| 方法 | 含义 |
|---|---|
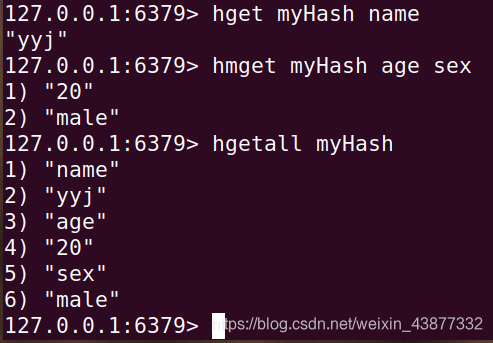
| hget key field | 返回指定 key 中 field 的值 |
| hmget key filed[field2…] | 返回指定 key 中多个 field 的值 |
| hgetall key | 返回指定 key 中所有 field-value |
2.3 删除
| 方法 | 含义 |
|---|---|
| hdel key field[field2…] | 删除指定 key 一个或多个 field |
| del key | 清空 Hash |
2.4 扩展命令
| 方法 | 含义 |
|---|---|
| hexists key field | 判断指定 key 中 field 是否存在 |
| hlen key | 返回指定 key 中 field 的数量 |
| hkeys key | 获取指定 key 中所有的 field |
| hvals key | 获取指定 key 中所有的 value |
127.0.0.1:6379> hmset myHash name yyj age 20 sex male
OK
127.0.0.1:6379> hexists myHash name
(integer) 1
127.0.0.1:6379> hexists myHash unknown
(integer) 0
127.0.0.1:6379> hlen myHash
(integer) 3
127.0.0.1:6379> hkeys myHash
1) "name"
2) "age"
3) "sex"
127.0.0.1:6379> hvals myHash
1) "yyj"
2) "20"
3) "male"Hash底层的数据结构实现有两种:
- 一种是
ziplist,当存储的数据操作配置的阈值时就是转用hashtable的结构,比较消耗性能; - 另一种是
hashtable,会消耗比较多的内存空间。
Redis 的Hash采用链地址法来处理冲突,没有用到红黑树优化,被分配到同一索引上的多个键值对会连接成一个单向链表;
在对哈希表进行扩展或收缩操作时,程序需要将现有哈希表包含的所有键值对refresh到新的哈希表里面,并且这个rehash过程并不是一次性地完成, 而是渐进式完成的。
在渐进式rehash执行期间,新添加到字典的键值对一律会被保存到ht[1]里面,而ht[0]则不再进行任何添加操作,这一措施保证了ht[0]包含的键值对数量随着rehash操作的执行而最终减少为0。
三、List 类型
C语言内部没有内置链表这种数据结构,所以Redis自己构建了链表的实现,Redis 的 List 类型有点像 Java 中的 LinkedList,内部实现是一个双向链表,双向链表的知识点参考文章:《数据结构 第二章 线性表》。
3.1 添加
| 含义 | 方法 |
|---|---|
| 从左端添加多个value | lpush key value[value2…] |
| 从右端添加多个value | rpush key value[value2…] |
注: 如果 key 不存在会先创建 key,然后添加。
3.2 查看
| 含义 | 方法 |
|---|---|
| 获取 list 从 start 到 end 的值 | lrange key start end |
| 获取 list 中元素数量 | llen key |
因为 List 内部是一个双向链表,因此链表首元素下标为0,尾元素下标为-1,因此查看所有元素即:lrange key 0 -1。
3.3 删除
| 含义 | 方法 |
|---|---|
| 返回并弹出左端元素 | lpop key |
| 返回并弹出右端元素 | rpop key |
注: 如果 key 不存在,返回nil。
3.4 扩展命令
3.4.1 添加前检查 key 的存在性
| 含义 | 方法 |
|---|---|
| 从左端添加多个 value | lpushx key value[value2…] |
| 从右端添加多个 value | rpushx key value[value2…] |
这两个方法加了 x 的和之前不加 x 的不同之处是:如果 key 不存在,将不进行插入。
127.0.0.1:6379> del myList
(integer) 1
127.0.0.1:6379> lpushx myList a b c
(integer) 0
127.0.0.1:6379> lrange myList 0 -1
(empty list or set)3.4.2 根据 value 删除
| 含义 | 方法 |
|---|---|
| 删除 count 个值为 value 的元素 | lrem key count value |
若 count > 0,则从左到右删除:
127.0.0.1:6379> rpush myList 1 2 1 3 5 1
(integer) 6
127.0.0.1:6379> lrange myList 0 -1
1) "1"
2) "2"
3) "1"
4) "3"
5) "5"
6) "1"
127.0.0.1:6379> lrem myList 2 1
(integer) 2
127.0.0.1:6379> lrange myList 0 -1
1) "2"
2) "3"
3) "5"
4) "1"若 count < 0,则从右向左删除:
127.0.0.1:6379> rpush myList 1 2 1 3 5 1
(integer) 6
127.0.0.1:6379> lrange myList 0 -1
1) "1"
2) "2"
3) "1"
4) "3"
5) "5"
6) "1"
127.0.0.1:6379> lrem myList -2 1
(integer) 2
127.0.0.1:6379> lrange myList 0 -1
1) "1"
2) "2"
3) "3"
4) "5"若 count = 0,删除所有:
127.0.0.1:6379> rpush myList 1 2 1 3 5 1
(integer) 6
127.0.0.1:6379> lrange myList 0 -1
1) "1"
2) "2"
3) "1"
4) "3"
5) "5"
6) "1"
127.0.0.1:6379> lrem myList 0 1
(integer) 3
127.0.0.1:6379> lrange myList 0 -1
1) "2"
2) "3"
3) "5"3.4.3 根据下标设置 value
| 含义 | 方法 |
|---|---|
| 设置下标为 index 的元素值。0代表最左边元素,-1代表最右边元素,下标不存在时抛出异常。 | lset key index value |
127.0.0.1:6379> rpush myList 1 2 3
(integer) 3
127.0.0.1:6379> lset myList 1 5
OK
127.0.0.1:6379> lrange myList 0 -1
1) "1"
2) "5"
3) "3"
127.0.0.1:6379> lset myList 3 5
(error) ERR index out of range3.4.4 相对于某元素插入 value
| 含义 | 方法 |
|---|---|
| 在 pivot 元素前插入value | linsert key before pivot value |
| 在 pivot 元素后插入value | linsert key after pivot value |
注:如果 pivot 不存在,不插入。
127.0.0.1:6379> rpush myList 1 2 3
(integer) 3
127.0.0.1:6379> linsert myList before 2 a
(integer) 4
127.0.0.1:6379> linsert myList after 2 b
(integer) 5
127.0.0.1:6379> lrange myList 0 -1
1) "1"
2) "a"
3) "2"
4) "b"
5) "3"3.4.5 将链表 A 右边元素移出并添加到链表B 左边
| 含义 | 方法 |
|---|---|
| 将链表 A 右边元素移出并添加到链表 B 左边 | rpoplpush listA listB |
127.0.0.1:6379> rpush myListA 1 2 3
(integer) 3
127.0.0.1:6379> rpush myListB a b c
(integer) 3
127.0.0.1:6379> rpoplpush myListA myListB
"3"
127.0.0.1:6379> lrange myListA 0 -1
1) "1"
2) "2"
127.0.0.1:6379> lrange myListB 0 -1
1) "3"
2) "a"
3) "b"
4) "c"
127.0.0.1:6379> rpoplpush myListA myListA
"2"
127.0.0.1:6379> lrange myListA 0 -1
1) "2"
2) "1"链表被广泛用于实现Redis的各种功能,比如 :列表键,发布于订阅,慢查询,监视器等;Redis的链表实现是双向链表,可以用于保存各种不同类型的值,可以直接获得头尾节点,常数时间复杂度获得链表长度。
3.5 特点
- 双端:具有前置节点和后置节点的引用,获取这两个节点时间复杂度都是O(1);
- 无环:表头节点的prev指针和表尾节点的next指针都指向NULL,对链表的访问都是以NULL结束;
- 带链表长度计数器:通过len属性获取链表长度的时间复杂度为O(1);
- 多态:可以保存各种不同类型的值。
四、Set 类型
Redis 的 Set 类型和 Java 中的 Set 类型一样,它具有两个重要的特点:无序性和唯一性,具体不再赘述。
4.1 基本操作
| 含义 | 方法 |
|---|---|
| 向 set 中添加成员,如果成员已存在,不再添加 | sadd key member[member2…] |
| 向 set 中删除成员,如果不存在,也不会报错 | srem key member[member2…] |
| 获取 set 中所有成员 | smembers key |
| 判断指定成员是否存在于 set 中 | sismember key member |
127.0.0.1:6379> sadd mySet 1 2 3
(integer) 3
127.0.0.1:6379> smembers mySet
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> srem mySet 2 3 5
(integer) 2
127.0.0.1:6379> smembers mySet
1) "1"
127.0.0.1:6379> sismember mySet 1
(integer) 1
127.0.0.1:6379> sismember mySet 2
(integer) 04.2 集合操作
| 含义 | 方法 |
|---|---|
| 集合的差集 | sdiff key1 key2[key3…] |
| 集合的交集 | sinter key1 key2[key3…] |
| 集合的并集 | sunion key1 key2[key3…] |
127.0.0.1:6379> sadd mySet1 a b c 1
(integer) 4
127.0.0.1:6379> sadd mySet2 1 2 3 b
(integer) 4
127.0.0.1:6379> sdiff mySet1 mySet2
1) "a"
2) "c"
127.0.0.1:6379> sdiff mySet2 mySet1
1) "2"
2) "3"
127.0.0.1:6379> sinter mySet1 mySet2
1) "1"
2) "b"
127.0.0.1:6379> sunion mySet1 mySet2
1) "c"
2) "1"
3) "b"
4) "2"
5) "a"
6) "3"4.3 扩展命令
| 含义 | 方法 |
|---|---|
| 求 set 中成员数量 | scard key |
| 随机返回一个成员 | srandmember key |
| 将多个集合的差集存储在 desc 中 | sdiffstore desc key1 key2[key3…] |
| 将多个集合的交集存储在 desc 中 | sinterstore desc key1 key2[key3…] |
| 将多个集合的并集存储在 desc 中 | sunionstore desc key1 key2[key3…] |
127.0.0.1:6379> smembers mySet1
1) "a"
2) "c"
3) "1"
4) "b"
127.0.0.1:6379> smembers mySet2
1) "3"
2) "b"
3) "2"
4) "1"
127.0.0.1:6379> scard mySet1
(integer) 4
127.0.0.1:6379> srandmember mySet1
"c"
127.0.0.1:6379> sdiffstore mySet3 mySet1 mySet2
(integer) 2
127.0.0.1:6379> smembers mySet3
1) "a"
2) "c"五、SortedSet 类型
SortedSet 和 Set 的区别是,SortedSet 中每一个成员都有一个 score(分数)与之关联,Redis 通过 score 来为集合中的元素进行排序(默认为升序)。
它的存储方式有两种:
- 压缩列表(ziplist)结构:member和score顺序存放并按score的顺序排列;
- skiplist和dict的结合:skiplist是一种跳跃表结构,用于有序集合中快速查找,dict用来存储元素信息,并且dict的访问时间复杂度为O(1)。
Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成,其中zskiplist用于保存跳跃表信息(比如表头结点、表尾节点、长度),而zskiplistNode则用于表示跳跃表节点。
5.1 添加/获取元素
| 含义 | 方法 |
|---|---|
| 添加成员。如果成员存在,会用新的 score 替代原有的 score,返回值是新加入到集合中的成员个数 | zadd key score member[score2 member2… ] |
| 获取指定成员的 score | zscore key member |
| 获取 key 中成员个数 | scard key |
| 获取集合中下标从 start 到 end 的成员,[withscores]表明返回的成员包含其 score | zrange key start end[withscores] |
| 上面方法的反转 | zrevrange key start end[withscores] |
127.0.0.1:6379> zadd mySort 82 wangnima 100 cat 33 dog 43 jitwxs 80 zhouyang 60 liuchang
(integer) 6
127.0.0.1:6379> zscore mySort jitwxs
"100"
127.0.0.1:6379> zcard mySort
(integer) 6
127.0.0.1:6379> zrange mySort 0 -1
1) "dog"
2) "liuchang"
3) "zhouyang"
4) "wangnima"
5) "cat"
6) "jitwxs"
127.0.0.1:6379> zrange mySort 0 -1 withscores
1) "dog"
2) "33"
3) "liuchang"
4) "60"
5) "zhouyang"
6) "80"
7) "wangnima"
8) "82"
9) "cat"
10) "100"
11) "jitwxs"
12) "100"
127.0.0.1:6379> zrevrange mySort 0 -1 withscores
1) "jitwxs"
2) "100"
3) "cat"
4) "100"
5) "wangnima"
6) "82"
7) "zhouyang"
8) "80"
9) "liuchang"
10) "60"
11) "dog"
12) "33"5.2 删除元素
| 含义 | 方法 |
|---|---|
| 删除成员 | zrem key member[member2…] |
| 按照下标范围删除成员 | zremrangebyrank key start stop |
| 按照 score 范围删除成员 | zremrangebyscore key min max |
127.0.0.1:6379> zrem mySort wangnima
(integer) 1
127.0.0.1:6379> zcard mySort
(integer) 5
127.0.0.1:6379> zrange mySort 0 -1
1) "dog"
2) "liuchang"
3) "zhouyang"
4) "cat"
5) "jitwxs"
127.0.0.1:6379> zremrangebyrank mySort 0 2
(integer) 3
127.0.0.1:6379> zrange mySort 0 -1
1) "cat"
2) "jitwxs"
127.0.0.1:6379> zrange mySort 0 -1 withscores
1) "dog"
2) "33"
3) "jitwxs"
4) "43"
5) "liuchang"
6) "60"
7) "zhouyang"
8) "80"
9) "wangnima"
10) "82"
11) "cat"
12) "100"
127.0.0.1:6379> zremrangebyscore mySort 50 85
(integer) 3
127.0.0.1:6379> zrange mySort 0 -1 withscores
1) "dog"
2) "33"
3) "jitwxs"
4) "43"
5) "cat"
6) "100"5.3 扩展方法
| 含义 | 方法 |
|---|---|
| 返回 score 在[min,max]的成员并按照 score 排序。[withscores]:显示 score;[limit offset count]:从 offst 开始返回 count 个成员 | zrangebyscore key min max[withscores] [limit offset count] |
| 设置指定成员增加的分数,返回值是修改后的分数 | zincrby key increment member |
| 获取分数在[min,max]的成员数量 | zcount key min max |
| 返回成员在集合中的排名(升序) | zrank key member |
| 返回成员在集合中的排名(降序) | zrevrank key member |
127.0.0.1:6379> zrange mySort 0 -1 withscores
1) "dog"
2) "33"
3) "jitwxs"
4) "43"
5) "liuchang"
6) "60"
7) "zhouyang"
8) "80"
9) "wangnima"
10) "82"
11) "cat"
12) "100"
127.0.0.1:6379> zrangebyscore mySort 30 86 limit 2 3
1) "liuchang"
2) "zhouyang"
3) "wangnima"
127.0.0.1:6379> zcount mySort 0 60
(integer) 3
127.0.0.1:6379> zincrby mySort 17 jitwxs
"60"
127.0.0.1:6379> zrank mySort jitwxs
(integer) 1
127.0.0.1:6379> zrevrank mySort jitwxs
(integer) 45.4 跳跃表
- 搜索:从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么往下找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,直到找到最底层的最后一个节点,如果找到则返回,反之则返回空;
- 插入:首先确定插入的层数,有一种方法是假设抛一枚硬币,如果是正面就累加,直到遇见反面为止,最后记录正面的次数作为插入的层数,当确定插入的层数k后,则需要将新元素插入到从底层到k层;
- 删除:在各个层中找到包含指定值的节点,然后将节点从链表中删除即可,如果删除以后只剩下首尾两个节点,则删除这一层。
六、key 的通用命令
| 含义 | 方法 |
|---|---|
| 获取所有于 pattern 匹配的 key。*:任意一个或多个字符,?:任意一个字符 | keys pattern |
| 删除指定 key | del key[key2…] |
| 判断 key 是否存在 | exists key |
| 为 key 重命名 | rename key newKey |
| 设置过期时间(单位s) | expire key |
| 获取key 剩余的过期时间(单位s)。若没有设置过期时间,返回-1;超时不存在返回-2 | ttl key |
| 获取 key 类型,key 不存在返回none | type key |
注:如果你设置了一个 key 的过期时间,如果又不想让它过期,可以执行命令 persist key。
127.0.0.1:6379> keys *
1) "unknown"
2) "mySet2"
3) "float_num"
4) "myListB"
5) "mySet3"
6) "userName"
7) "myListA"
8) "int_num"
9) "mySort"
10) "mySet1"
127.0.0.1:6379> del unknown
(integer) 1
127.0.0.1:6379> type myListA
list
127.0.0.1:6379> rename myListA myList
OK
127.0.0.1:6379> exists myListA
(integer) 0
127.0.0.1:6379> ttl mySort
(integer) -1
127.0.0.1:6379> expire mySort 30
(integer) 1
127.0.0.1:6379> ttl mySort
(integer) -2
127.0.0.1:6379> keys *
1) "mySet2"
2) "myList"
3) "float_num"
4) "myListB"
5) "mySet3"
6) "userName"
7) "int_num"
8) "mySet1"七、总结
大多数情况下,Redis使用简单字符串SDS作为字符串的表示,相对于C语言字符串,SDS具有常数复杂度获取字符串长度,杜绝了缓冲区的溢出,减少了修改字符串长度时所需的内存重分配次数,以及二进制安全,能存储各种类型文件,并且还兼容部分C语言函数。
通过链表设置不同类型的特定函数,Redis链表可以保存各种不同类型的值,除了用作列表键,还在发布与订阅,慢查询,监视器等方面发挥作用;
Redis的字典底层使用哈希表实现,每个字典通常有两个哈希表,一个平时使用,另一个用于rehash操作,使用链地址法解决哈希冲突;
跳跃表通常是有序集合的底层实现之一,表中的节点按照分值大小进行排序;
整数集合是集合键的底层实现之一,底层由数组构成,升级特性能尽可能减少内存;
压缩链表是Redis为节省内存而开发的顺序型数据结构,通常作为列表键和哈希键的底层实现之一。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!